针对于“发布工程(Release Engineer)”,也许大家并不陌生。如维基百科中介绍:
Release engineering, frequently abbreviated as RE or as the clipped compound Releng, is a sub-discipline in software engineering concerned with the compilation, assembly, and delivery of source code into finished products or other software components. Associated with the software release life cycle, it was said by Boris Debic of Google Inc.
对于一个有着庞大开发团队的成熟公司来说,构建工程显得格外重要。这样一个或者若干个由成百上千个开发成员支持的软件产品来说,构建与发布无非是非常严峻的考验。
然而,目前而言,我们团队在构建发布上仍有着很大的提升空间。
我们的问题
首先介绍下我们组。我们组负责微博的话题业务,每天有着成百上千万的访问量级。核心开发人员一共有 15 人左右。然而,尽管是 15 人的团队,软件的构建与发布流程也显得很重要。
在刚进入团队时,并没有构建概念,同样在发布流程上做的也不够衔接与完善。当有产品提出需求之后,技术 Leader 在进行需求拆分后合理分配给每个开发人员。之后,每个开发人员将以自己的姓名与时间从话题业务版本库的主干上 Check Out 一个分支。待开发完成之后,进入测试申请流程。常规情况下要进行三轮的测试:分支内网测试、分支仿真测试与主干回归测试。在这三轮测试顺利通过之后,我们将通过上线系统(QuikBuild)进入上线流程。
至始至终我们都遵循着上面的流程,然而,会发现如下问题。
- 每个需求都有着规定的上线日期,在测试流程上我们不得不优先安排最近上线的需求(以功能为周期);
- 当 A 需求合并主干进行回归测试时,那么 B 需求只能等待 A 需求顺利通过回归测试并通过线上验证才能进入回归流程。否则,如果 A 需求出现 bug,那么 B 需求不得不在主干上被回滚掉;
- 若需要处理线上紧急 bug,我们不得不将主干上未上线(测试中)的代码进行回滚,才能在主干上修复 bug 后进行上线;
- 每一个功能的测试,测试同学都需要部署一套测试环境。尽管环境可以复用,但至少需要重新部署代码并保证环境可用。同时,每个功能的测试都需要一套独立的测试环境。这大大降低了测试效率与测试资源利用率;
- 从开发、提交测试、测试、上线到线上验证的每个环节,都需要人为的干预。同时,每个需求的开发信息、开发进度、测试进度、测试bug、上线情况都需要人为地每日进行反馈。每个环节的连接都是断开的。所以,我们每日都需要进行一些琐碎但有意义的工作。不但加大了时间成本,更降低了整体项目的透明度与管理效率。
面对上面的问题,我们及时地做了调整。首先,在会议讨论后,我们决定先在项目中融入持续集成与持续交付的概念。
发布工程
持续集成(Continuous Integration ,CI)
在传统软件开发过程中,集成通常发生在每个人都完成了各自的工作之后。在项目尾声阶段,通常集成还要痛苦的花费数周或者数月的时间来完成。持续集成是一个将集成提前至开发周期的早期阶段的实践方式,让构建、测试和集成代码更经常反复地发生。
持续集成意味着一个在家用笔记本编写代码的开发人员(嘿,史蒂夫)和另一个在办公室编程的开发人员(嘿,安妮)可以为同样的产品分别地编写软件,将其改动整合在一个叫做源存储库的地方。他们可以从各自编写的部分构建出组合的软件,并且按照他们期望的方式来测试软件。
开发人员通常使用一种叫做IC Server 的工具来做构建和集成。持续集成要求史蒂夫和安妮能够自测代码。分别测试各自代码来保证它能够正常工作,这些测试通常被称为单元测试(Unit tests)。
代码集成以后,当所有的单元测试通过,史蒂夫和安妮就得到了一个绿色构建(green build)。这表明他们已经成功地集成在一起,代码正按照测试预期地在工作。然而,尽管集成代码能够成功地一起工作了,它仍未为生产做好准备,因为它没有在类似生产的环境中测试和工作。在下面持续交付部分你可以了解到持续集成后面发生了什么。
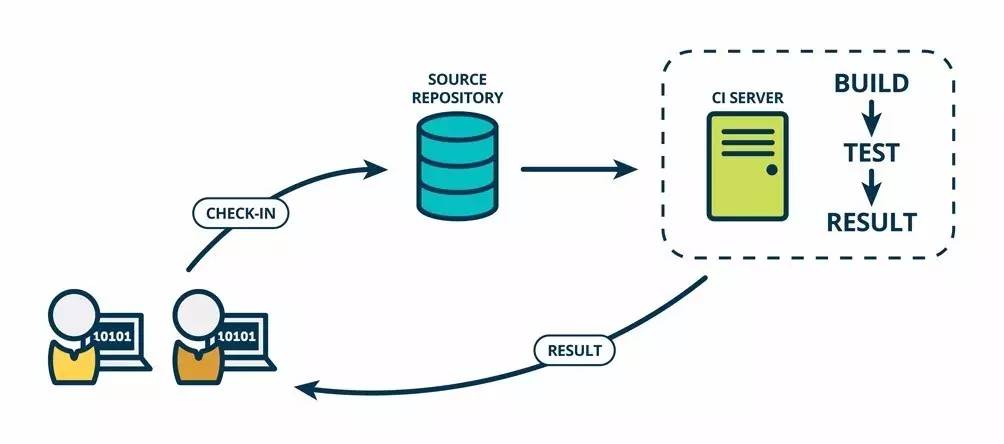
考虑到实践持续集成,史蒂夫和安妮必须频繁地登记主代码仓库、集成和测试他们的代码。通常一小时很多次,并且每天最少一次。
持续集成的好处是,集成不再是个头疼事。软件在一直被编写和集成。在持续集成之前,集成发生在创建过程的结尾阶段,一次性完成,并且不知道要耗时多久。而现在持续集成,每天都融入到了工作方式当中。
持续交付(Continuous Delivery,CD)
让我们说回到我们的两位开发人员,史蒂夫和安妮。持续交付意味着每次史蒂夫或安妮修改、整合和构建代码时,也同时在类似于生产环境中自动测试了这段代码。我们通常将这个在不同环境发布和测试的过程叫做部署流水线。通常部署流水线有一个开发环境,一个测试环境,一个准生产环境,但是这些阶段会根据不同的团队、产品和组织而变化。例如,Mingle团队有一个阶段叫做“纸杯蛋糕”的准生产环境,而Etsy的准生产环境叫做“公主”。
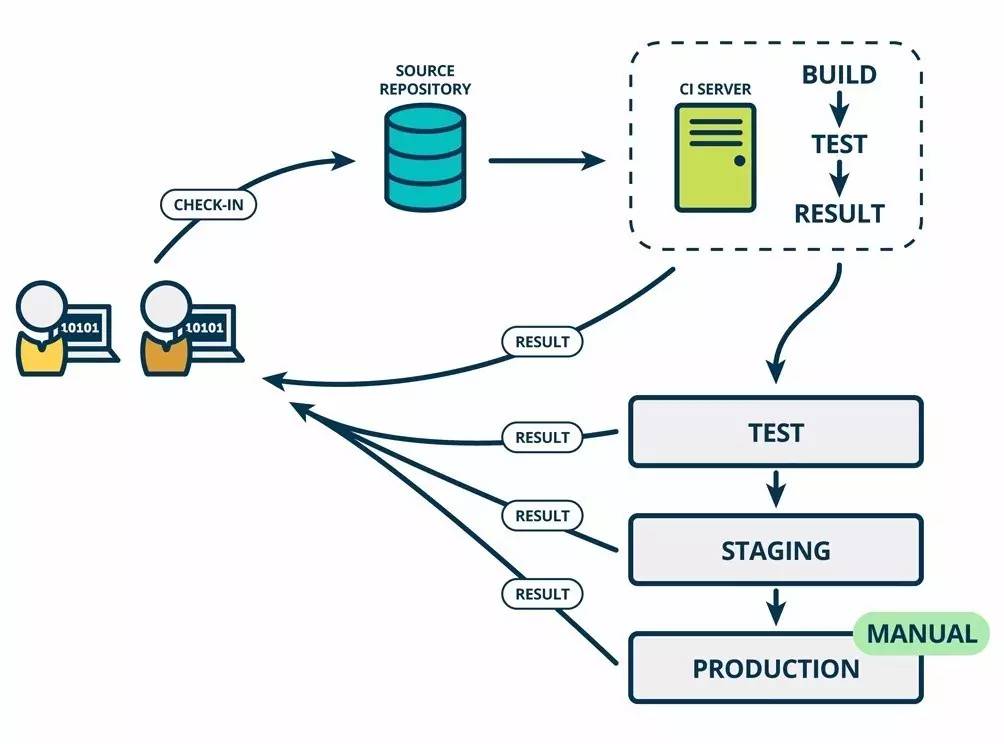
在不同的环境下,安妮和史蒂夫写的代码被分别进行测试。当代码部署到生产环境它就开始了工作,这给予了他们更多的信心。并且只有当代码通过前一个环境的测试才会进入到下一个部署流水线的环境当中去。通过这种方式,安妮和史蒂夫将会从每个环境中测试并得到新的反馈,如果有失败,他们也可以在代码被应用到生产环境之前更加容易地发现问题并且修正它。
针对上述概念,网上也有着不同程度的软件产品。但是,我们并不打算直接采用开源产品为我们服务。原因有二:
- 当发现问题时,由于产品本身的技术逻辑并不熟悉,导致排查成本大;
- 当对开源产品进行二次改造时,也会加大开发成本。
基于如上原因,我们决定利用PHP作为主要工具,“因地制宜”地开发一套持续集成,持续交付的构建工具。
首先,我们的构建系统将于每日的23点进行项目源代码的编译。由于我们的项目采用的是解释型语言 – PHP,所以在编译这个阶段我们进行了语法检查。随后,进行项目提交(commit)信息的提取,以及一些其他描述信息的提取。最后,根据当前的构建情况,发送相应的构建邮件给相关人员,包含:开发、测试、产品、领导以及其他相关业务人员。

紧接着,将进行BVT测试。随后将发送一封测试结果报告邮件。

至此,我们完成了项目上的持续集成与持续交付的环节。在前期,我们的持续集成与交付流程并不是很稳定。几乎每天都需要人为进行系统调整。然而,逐渐地系统稳定起来了。目前这些概念仍不能完全解决我们上述提到的问题。所以,我们进一步的探索,将持续部署纳入到我们的项目周期中。
持续部署(Continuous Deployment)
史蒂夫或者安妮所做的每个改动,都是通过测试环节,才自动投入生产环节。这个PDF对其进行了很详细的描述:(http://www.paulhammond.org/2010/06/trunk/alwaysshiptrunk.pdf)。为了达成持续部署,首先需要持续交付。同时,持续交付提高了业务的敏捷性,这才是真正实现业务导向的捷径。
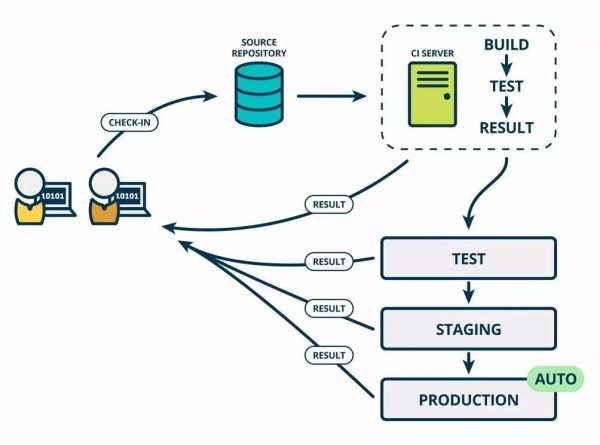
在将上述概念融入到我们的项目中来之前,我们集体讨论了,在“持续部署”概念下工作的几点原则。
以时间为周期
在软件发布的过程中,我们将以时间为周期。比如,下文中提到的发布流程。我们将以一周为单位,每周二与周四分别进行两次上线。如果功能A开发完成,并通过测试,那么自然就进入到本周期的持续部署的流程中来:如果功能A没有开发完成或者未完成测试,那么就需要进入到下一个持续部署周期的流程中。
相对于本概念,我们目前的项目是以功能为周期。比如,只有等待A功能开发完成并通过测试流程后,我们才可以进行上线流程。上线是需要等待功能的。所以,从这个点上来说,这次对于话题组的发布流程是个不小的改变。
用户驱动发布
如持续部署图中的”AUTO”,这次的自动发布流程改造,不会直接全量将代码自动推送到线上。因为,这样的话,如果线上出现问题,那么影响范围将是全部用户,只能进行回滚,且无法挽回。
然而,我们将会在每个上线环节中进行两次上线。第一次,将服务推送给大约5%的用户。之后,将根据当前那%5的灰度用户的反馈,以及服务器的负载、重要接口的响应与产品、测试同学的反馈等信息,来决定下一步是全量发布还是回滚。这个验证周期我们暂定为4个小时。
这样以来,尽管会出现问题,也只是那5%的用户而已。我们总是会在出现严重情况之前,进行修复。
版本永远在迭代
每个产品需求永远可以在下一版本中发布(或者下下一个版本)。我们每个版本都会连续不间断的进行着持续交集成、交付与部署。每个版本中的功能也不例外。遵循这个原则,因为这是规矩。没有规矩,不成方圆。
当然,在工作中我们总是会遇到那些话“这个需求老板催得特别紧,必须今天上线”。

对于这种情况,我们只能加班加点,有时第二天才下班,将其完成并上线。但是,这带来的往往是员工的工作效率降低。如果,我们的产品了解项目的版本周期,那么我想项目将更健康,大家的工作态度也将更为乐观。
优先回滚
当线上出现bug时,优先进行回滚操作,而不是在当前情况下进行bug的修复。
在上述的原则基础上,我们参考了facebook中desktop web项目运行了8年的发布流程。
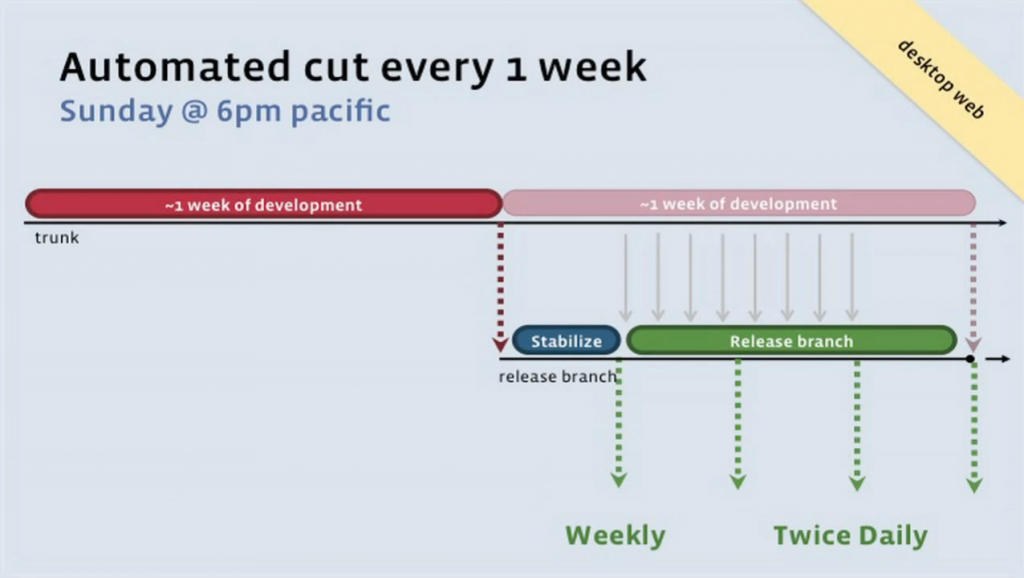
我们每个开发人员将经过测试且稳定的代码提交到集成分支(develop branch)(对应于图中的trunk ),随后持续部署系统将在每周日的下午6点自动进行一次操作,从当前主干检出一个预发布分支(release branch)。同时将集成分支下的功能merge到预发布分支中。当然,这个merge的过程也需要考虑到人为因素。
随后,周一到周二早上将在持续部署的模拟生产(仿真)环境中进行稳定性测试。在通过稳定性测试后,分别在周二和周四进行上线流程。
每次的上线流程中,首先将服务推送给5%左右的用户。此时,系统将通过邮件周知所有相关人员。随后将进行4个小时的验证阶段。4个小时之后,系统将根据反馈情况,进行回滚或者全量上线操作。此时,仍然通过邮件周知所有相关人员。
在这个周期中,系统将会接收到很多bug的修复,简单功能的提交(不接收未经测试的较大功能)。保证系统持续健康的状态。
其实,这张图片是2014年@Chuckr在Google的一次演讲中提到的,“图中的流程已经在facebook运营了整整六年,从未改变过”。如果大家感兴趣,请点击https://www.youtube.com/watch?v=Nffzkkdq7GM。
然而,在这种发布流程模式下,具体到开发流程是怎么样的呢?
开发工作流
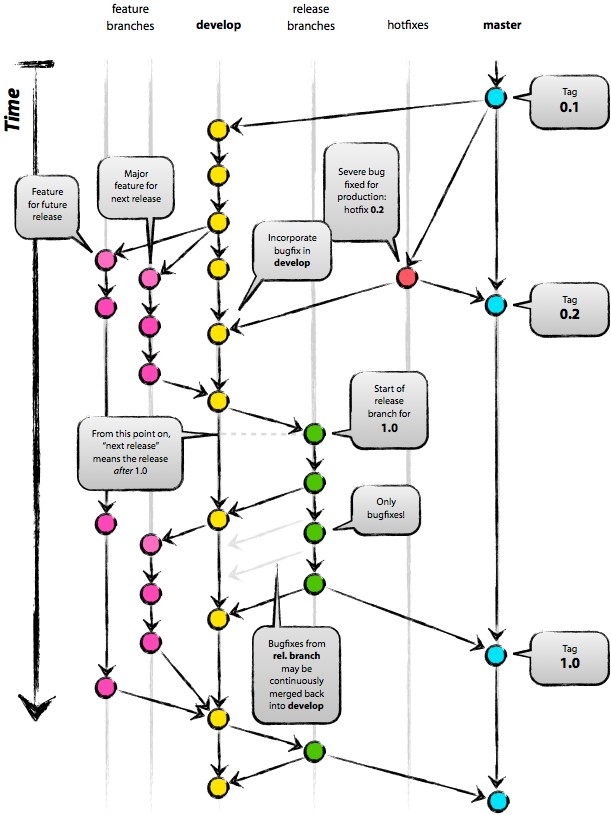
首先,明确下分支概念:
- 红色:功能分支
- 黄色:集成分支
- 绿色:预发布分支
- 红色:线上bug分支
- 蓝色:主干
如上图,粉红色的分支为我们日常的功能分支,这个分支将以我们的名称、日期与功能描述进行命名。比如:hx_20160816_newFeatureOfSomeWhat。
在我们将功能开发完成之后,将功能分支合并到集成分支,如上图的黄色分支(develop)。在这期间,集成分支在不断地进行持续集成与持续交付。
在每个星期日下午6点,持续部署系统将会从主干(trunk)检出一个预发布分支(release branch)。此时,主干的内容往往是干净的。接着会将当前的集成分支合并到预发布分支。同时,如果有其他分支已经通过测试,也可以提交到预发布分支中来。
在接下来的一周中,我们将会在预发布分支中进行无数次的bug修复与小功能提交。在这个期间(周一到周五),不再向预发布分支中提交未经测试的大功能。
如果线上出现问题需要紧急修复,那么我们将从主干检查一个hotfix分支。在修复之后,分别合并到主干与其他分支。
总结
我们正在完善上面的概念,并将其融入到日常工作中来。希望在不断地实践中成长,稳定与发展。如果您有相关的建议和见解,欢迎沟通。
相关资料:微博话题日构建 PPT
参考文章: